In late 2025, Andrej Karpathy, one of the founding members of OpenAI, wrote that he had “never felt this much behind as a programmer.”
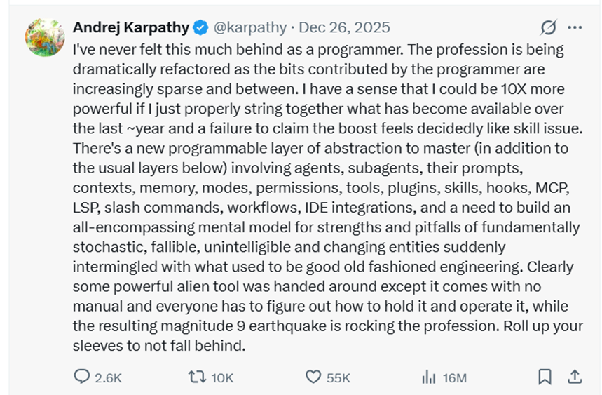
Read that again. The man who helped build modern AI was telling the world that software engineering was being refactored under his feet, and that there was an entirely new “programmable layer of abstraction” to master: agents, sub-agents, prompts, context, memory, modes, permissions, tools, plugins, skills, hooks, MCP, slash commands, IDE integrations.
Six months later, this is no longer fringe. It is how serious software gets built.
If you are an executive trying to understand what your engineering teams are actually doing, a recruiter trying to figure out which skills are now table stakes, a product leader sponsoring AI initiatives, or an engineer who senses you are losing time to a tooling shift you have not fully internalized, this article is for you.
I have spent months working through what is real, what is hype, and what holds up in production. Here is the honest, vendor-neutral map.
The shift, in one paragraph
In 2022, GitHub Copilot suggested the next few lines of code as you typed. The boundary was clear: the developer drove, the model nudged.
In 2026, you give a tool a goal, things like “refactor this authentication module to support OIDC”, “investigate why this test is flaky”, or “add pagination to this list view”, and it plans, reads files, writes files, runs shell commands, executes tests, searches the web, and calls external services until the goal is met.
The developer steps back from typing each token and steps up to a different role: defining intent, supervising, reviewing diffs, course-correcting, and accepting or rejecting outcomes.
This is agentic coding. And it is changing what it means to be an engineer.
Three terms people keep confusing
You will hear these used interchangeably. They are not the same thing.
Vibe coding (early 2025): coined by Andrej Karpathy. The loose, exploratory style of giving a model a high-level prompt and shipping whatever comes out without close inspection. Pure form: throwaway prototyping.
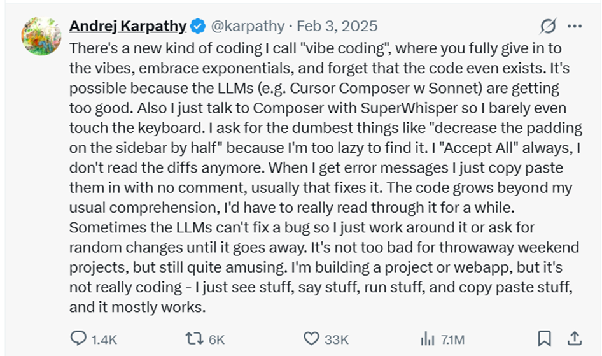
Vibe engineer (late 2025): popularized by Simon Willison as a corrective. A professional who uses agents to build real software, but with rigor: clear specs, tests, code review, accountability for what ships.
Agentic coder / agentic engineer (2026): the term most professionals now use. Someone who treats AI agents as collaborators inside a real engineering workflow.
Quick rule of thumb: if a noun ends in “coder” or “engineer” it is a person. If it ends in “agent” or “code” (as in “Claude Code”), it is a tool.
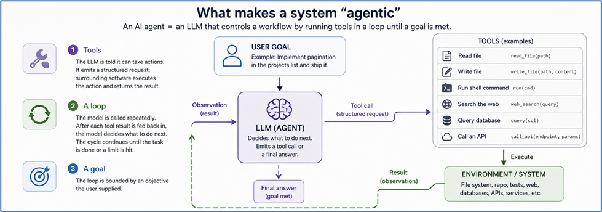
What actually makes a system “agentic”
Strip the marketing away and the working definition is simple:
An agent is a system in which a large language model controls a workflow by running tools in a loop until a goal is met.
Three pieces matter:
- Tools. The model is told it can take certain actions: read a file, write a file, run a shell command, query a database, call an API. The model does not perform these actions itself. It generates a structured request, and surrounding software actually executes the action and returns the result.
- A loop. Instead of being called once, the model is called repeatedly. After each tool call the result is fed back, the model decides what to do next, the cycle continues until the task is done or a budget is hit.
- A goal. The loop is bounded by an objective the user supplied.
This sounds modest. It is not. A model that can read your repository, run your tests, see the output, and try again is qualitatively different from one that can only suggest text. It is the difference between an assistant that drafts an email and one that can also send it, check the reply, and follow up.
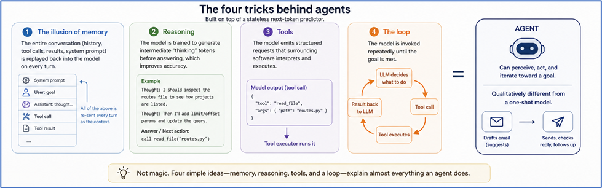
A piece of foundational truth most people get wrong
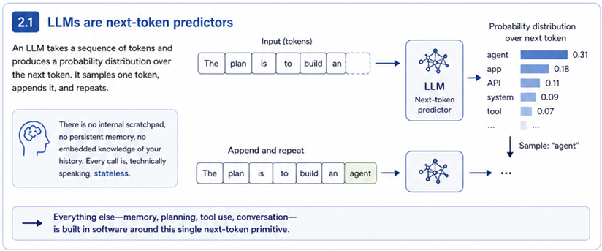
Large language models are stateless next-token predictors. Period.
There is no internal scratchpad. No persistent memory. No embedded knowledge of your history. Every API call is, technically speaking, stateless.
Everything else, the conversation that seems to remember what you said three turns ago, the agent that seems to be planning, the assistant that calls a tool and waits for the result, is built in software around that single next-token primitive.
Recognising this saves an enormous amount of confusion. When something feels like it “should have remembered” but did not, this is why.
Context is everything (and the window matters)
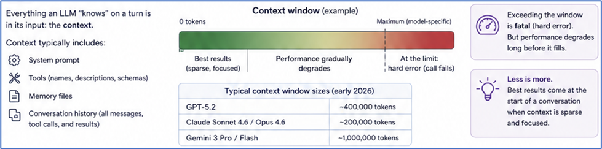
Whatever an LLM “knows” on a given turn is in its input. That input is called the context. It typically includes a system prompt, a description of available tools, persistent memory files, and the entire conversation history, including every message, every tool call, every result.
Each model has a maximum context size, the context window, measured in tokens. As of mid-2026:
- GPT-5.5 sits around 256K to 400K tokens depending on tier
- Claude Opus 4.7 and Sonnet 4.6 sit around 200K tokens
- Gemini 3.1 Pro extends to 1M to 2M tokens
Exceeding the window is a hard error. But here is what most people miss: long before the window fills, performance degrades. Models start losing coherence, forgetting earlier instructions, mixing up details. The best results almost always come at the start of a conversation, when the context is sparse and focused.
Less is more is a real principle, not a slogan.
This is why “context engineering”, deciding what goes into the input and what stays out, has replaced “prompt engineering” as the more useful term.
The single most important file in modern software development: AGENTS.md
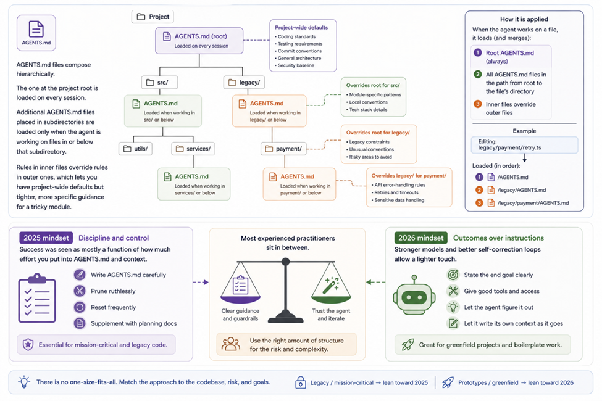
If there is one artefact that defines modern agentic coding, it is AGENTS.md (or CLAUDE.md, or GEMINI.md, same idea, different filename).
It is a Markdown file at the root of your project. The agent reads it on every session. It contains everything you would tell a new engineer joining the team:
- What the codebase does
- What conventions to follow
- How to run, build, and test it
- What never to touch
- What success looks like for the work
The industry is converging on AGENTS.md as the de facto standard. Markdown is the format of choice because it is human-readable, version-controllable, and language models are remarkably good at producing and consuming it.
A few things experienced practitioners have learned the hard way:
- Brevity is not stylistic, it is a practical optimization. Every word costs latency, money, and attention.
- Models follow clear, positive instructions more reliably than negative ones. “Prefer composition over inheritance” beats “avoid deep inheritance hierarchies.”
- Treat AGENTS.md like a garden. Prune ruthlessly. The model will introduce verbosity if you let it.
Hierarchically: a root AGENTS.md applies project-wide. Subdirectory AGENTS.md files apply only when the agent works in that subdirectory, and override the root. Useful for legacy modules with unusual conventions.
The three surfaces: how engineers actually talk to agents
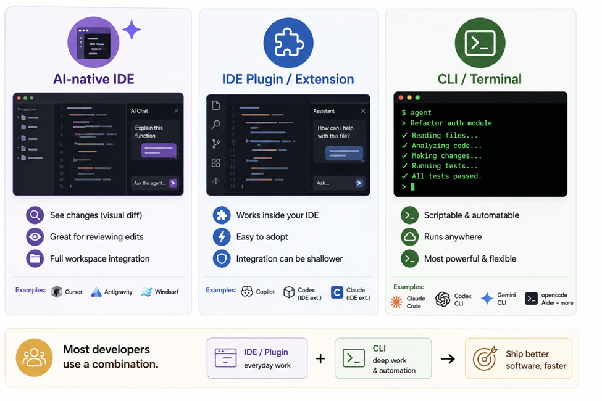
There are three distinct interfaces in production use today:
- AI-native IDEs. Cursor (the most prominent), Google’s Antigravity, Codeium’s Windsurf. Visually they look like VS Code (most are forks of it), but AI is woven through every panel. Strength: excellent visual diffs. Weakness: another editor to learn, another subscription.
- Plugins to existing IDEs. GitHub Copilot is the canonical example, and remains the most widely deployed coding assistant simply because every team is already on VS Code or JetBrains. OpenAI’s Codex and Anthropic’s Claude Code also offer extensions. Strength: zero switching cost. Weakness: agent integration can be shallower.
- Command-line interfaces (CLI), and this is where things have changed most. Claude Code, released by Anthropic, established this category. It started as a side project, blew up, and shifted the industry’s expectations. Today every major vendor ships one: Cursor CLI, Codex CLI, Gemini CLI, opencode, Aider, Goose, Amp.
CLIs grew quickly because they are scriptable (agents can be invoked inside larger pipelines, including by other agents), they run anywhere a terminal runs, and they integrate naturally with the unix tools senior engineers already use heavily.
The 2026 AI coding survey reported experienced developers using an average of 2.3 tools, and that number rises for senior practitioners. Most professionals combine an IDE plugin for everyday edits with a CLI for heavier autonomous work.
Modes: how much autonomy do you give it?
This is where workflow discipline lives.
Plan mode. The agent reads, analyzes, and produces a written plan. Files it will touch, steps it will take, questions to resolve. No code is written. You read, push back, edit. Use it whenever a task touches more than two or three files.
Approval mode. The agent asks before every action. Slow, but the right default for unfamiliar codebases or high-stakes changes.
Agent / execute mode. The agent acts within whatever permissions you have granted.
YOLO mode. “You only live once.” Blanket permission, agent runs, you watch (or don’t). Dominant for greenfield prototyping. Increasingly used for serious work too, but with safeguards: sandboxed environments, frequent commits, and an iron rule that you read every diff before merging to main.
Spec-driven development (SDD). Write a structured spec first, then let the agent work against it. GitHub’s Spec Kit, Kiro, BMAD, and OpenSpec all popularize variations. The intuition: models are excellent at pattern completion and very poor at mind-reading. A clear spec eliminates guessing.
Ralph loops. Named, half-affectionately, after Ralph Wiggum. Australian developer Geoffrey Huntley coined the term for wrapping the agent’s normal loop inside an outer loop with an evaluation step. The agent runs, an evaluator checks the goal, gaps become feedback, the agent runs again, sometimes ten or twenty times. Designed for tasks that take hours. Powerful, but if the agent is off the rails early, the loop will compound the damage.
Multi-agent orchestration. A planner agent, an implementer, a tester, a reviewer, all coordinating. This is genuinely impressive when it works, and it gets the most enthusiastic press coverage. As of mid-2026, productive use is concentrated in a small number of advanced teams on clearly bounded, parallelisable work. For most professional engineering, the sweet spot remains a single capable CLI agent with one or two narrow sub-agents.
The match-the-model rule: frontier models (Claude Opus 4.7, GPT-5.5, Gemini 3.1 Pro) tolerate YOLO well. Smaller or faster models produce subtle errors at a rate that overwhelms unsupervised workflows. With weaker models, work in smaller increments and watch every diff.
The modern agentic stack
Around the basic agent has grown a family of primitives that experienced practitioners now treat as core toolkit. None are required. Understanding them is the difference between using an agent as a slightly smarter Copilot and using it as a genuine collaborator.
MCP (Model Context Protocol). Released by Anthropic in November 2024, now supported across all major vendors. The pitch is that MCP is to AI tools what USB-C is to consumer electronics: a single standard that replaces dozens of vendor-specific integrations. Once a system speaks MCP, every MCP-aware agent can use it. As of 2026 there are MCP servers for GitHub, Slack, PostgreSQL, Stripe, Figma, Docker, Kubernetes, Notion, Salesforce, and well over two hundred others. For organizations standardizing their AI development stack, treating MCP as the default integration layer is now the dominant strategy.
Skills. Reusable instruction sets bundled for specific tasks. Auto-invoked by the agent when relevant. Enables progressive disclosure: a one-line description in AGENTS.md, full details only loaded when needed. Excellent for encoding hard-won team practices.
Hooks. Deterministic guardrails that run at lifecycle events. Pre-tool-call, post-write, session-start. Unlike AGENTS.md instructions (which are advisory), hooks are code that runs every time. They reject destructive shell commands, enforce file-write boundaries, force linters to pass. For teams deploying agents in environments where “oops” is not acceptable, hooks are not optional.
Slash commands. Saved prompts triggered by /name. The simplest and easiest entry point. Rule of thumb: if you type similar instructions more than twice, save them as a slash command.
Sub-agents. Separately-running agents invoked by a parent for narrow tasks like codebase exploration. The sub-agent reads twenty files in its own isolated context, returns a short summary. The thousands of tokens never enter the parent’s context. This is the practical answer to the context-window problem.
Plugins and marketplaces. Bundled distributions packaging skills, slash commands, hooks, and MCP servers. The layer that turns agentic coding from individual practice into shareable team capability.
The major platforms (a brief tour)
Cursor. The most commercially successful AI-native IDE. Polished diff workflow, excellent autocomplete, low learning curve for VS Code users. Higher subscription cost.
GitHub Copilot. Most widely deployed coding assistant by user count. Easiest adoption for any team already on the GitHub stack. Multi-model selector across Anthropic, OpenAI, and Google.
OpenAI Codex (GPT-5.5). Available across desktop app, CLI, VS Code extension, and cloud-delegated background agents. Strong on the hardest reasoning-heavy coding tasks. GPT-5.5, released April 2026, is OpenAI’s flagship for agentic coding, with improved instruction persistence across long tasks and better tool orchestration in multi-step pipelines.
Google Antigravity and Gemini CLI. Built around Gemini 3.1 Pro. The defining strength is long context, up to 1M to 2M tokens, qualitatively different from competitors when feeding in large bodies of code.
Claude Code (Anthropic). The CLI tool that defined the category. Terminal-first by design. Pioneered skills, plugins, sub-agents, hooks, and clean MCP integration. Now powered by Claude Opus 4.7, which Anthropic launched with stronger coding, better long-running task performance, and higher-resolution vision. The CLI-first design composes naturally with shell pipelines and scripting.
Open source. Aider, opencode, Cline, Continue.dev, OpenHands, Goose, Kimi CLI, Qwen Code. Lag the proprietary leaders by a few months on the most advanced features but offer transparency and provider independence. Often the only viable option for teams with strict data-handling requirements.
The single most consequential decision is usually not which tool, but which model. Most platforms support multiple models, and the same tool produces wildly different results depending on which one is driving.
Favour smart over fast. A slower, more accurate model produces a faster overall outcome than a quick model that needs three iterations. Trying to save on per-token cost by using a smaller model usually costs more in time and rework.
Principles that have held up across two years
Tools change. Models change. These have not.
1. You own the code.
The single most important principle, and the one most likely to be forgotten under deadline pressure. The model wrote it. You signed it. “The agent did it” is not a defense in code review, in production, or in a post-mortem.
The Jellyfin media server’s contribution policy is a frequently-cited example: AI-assisted contributions are welcome, but contributors must be able to explain every line, must keep diffs focused, must have tested the code, and may not just “let an LLM loose on the codebase with a vague vibe prompt and commit the result.” This is not anti-AI. It is a perfectly reasonable insistence that “easy to generate code” must not be dumped on reviewers as “hard to review code.”
2. Be the boss.
Treat the agent as an exceptionally enthusiastic, exceptionally tireless, but occasionally overconfident assistant. A good boss does five things:
- Sets the spec clearly. Vague briefs produce vague work.
- Starts simple. Build a minimum viable slice first.
- Works incrementally. Small steps, small diffs, frequent checkpoints.
- Refuses to get lazy. When the agent claims to have fixed a bug, demand a reproducing test that now passes, not a confident assertion.
- Handles frustration with style. Take a step back. Change the prompt. Change the approach. Change the model. Do not just keep yelling at it.
3. Reproduce, prove, fix, demonstrate.
When an agent claims to have fixed a bug, the right ritual is: ask it to reproduce the problem, prove the root cause, fix the root cause, and demonstrate the fix with a passing test. Skipping any of these four steps is how subtle bugs survive into production.
4. Match the workflow to the work.
Mission-critical, large-codebase, regulated work calls for plan mode, careful AGENTS.md, frequent context resets. Greenfield prototypes and boilerplate tolerate YOLO and Ralph loops.
For product managers and leaders: the 10x productivity stories that get cited are real for greenfield UI work. They are not real for complex backend changes in legacy systems with subtle constraints. There the gain is more like 20 to 40 percent (or 2x). That is still transformative, but it is not what some demos suggest.
Different advice for different audiences
For senior engineers. This tooling is, in many ways, built for you. You have the judgement to spot when the agent is wrong, the architectural sense to set good specs, the pattern recognition to catch subtle bugs in generated code. The biggest risks are not technical; they are habits. Watch for: skill atrophy from delegating everything (Karpathy himself has flagged this), lazy reviewing dulled by aesthetic perfection of LLM output, and forgetting the joy of typing code yourself. Stay current by occasionally taking a task all the way through by hand.
For more junior engineers. The risk is not atrophy of skills you already have, it is failing to develop them in the first place. Anthropic itself published a study showing junior developers using AI assistance learned the underlying technology significantly less well than those who did not. The rule that follows is simple: use the agent, but use it as a teacher as well as a coworker. Ask it to explain. Ask it why it chose this approach over that one. Push back. Be the curious, skeptical junior who treats the agent the way a wise non-technical manager treats their team. That is how you become senior.
For product managers and leaders.
- Calibrate expectations honestly. Demos are first-pass MVPs. Production-ready software still requires testing, review, security, and operational rigor. Agents make the first pass faster. They do not eliminate the rest of the SDLC.
- Invest in shared context. AGENTS.md, plugins, skills, slash commands compound. A team where every engineer curates their own is leaving most of the value on the table. Treat shared context like shared infrastructure, version-controlled, reviewed, distributed.
- Plan for governance from day one. If your engineers are running CLI agents with shell access against your repository, you have a new attack surface. Hooks, sandboxing, MCP allow-lists, audit logs, and clear policies on what can run unattended are easier to build in than to bolt on.
For recruiters and talent leaders. The skills that matter now are not just languages and frameworks. They are context engineering, prompt and spec writing, agent supervision, hook, skills and policy design, multi-agent orchestration patterns, and the judgment to know when not to use an agent. Engineers who can speak fluently about MCP, skills, AGENTS.md, plan mode versus YOLO, and Ralph loops versus GSD versus Superpowers are not optional hires for the next decade. They are the new baseline for senior IC roles.
What this means going forward
Agentic coding does not reduce the need for engineering judgement. If anything, it increases it. The cost of bad judgement is now compounded by the speed at which an agent can act on it.
What it changes is what engineering judgement gets to focus on:
- Less time on syntax, more time on architecture.
- Less time on boilerplate, more time on correctness.
- Less time on the obvious parts of the job, more time on the parts that are interesting because they are hard.
That is a good trade. Take it.
The central skill, whichever tool you settle on, is the same: the ability to direct, supervise, and integrate the work of a tireless, capable, occasionally overconfident collaborator. Call it agentic engineering, vibe engineering, or just engineering with extra steps. That skill is what the next decade of software work looks like.
The earlier you build the muscle, the better your work is going to feel.
Originally published on LinkedIn on May 11, 2026: Agentic Coding Is Real.